

Building an Artifacts System for Our LLM Data Agents
By: Orel Lazri, Senior Software Engineer
At Nexxen, our engineering teams are constantly exploring how AI can enhance the way our users interact with advertising data. As part of our nexAI DSP Assistant – our AI-powered data assistant – we implemented the ability to let users query and analyze campaign performance metrics. The initial implementation worked well for single questions, but we quickly discovered a fundamental challenge that was frustrating our users.
The Problem: When Every Question Starts from Scratch
Our AI data agent was capable of generating SQL queries, fetching results from our data warehouse, and presenting insights to users. However, when users started asking follow-up questions, the system’s response times noticeably increased.
Consider this scenario: a user asks, “Show me the spend and CPM for my campaigns during last Christmas.” The assistant queries the database, returns 500 rows of campaign data, and then the user sees a helpful summary. Then they ask a natural follow-up: “Filter that to just the top 10 by spend.”
Without a memory system, our assistant was stuck between starting from scratch each time a user asked a follow-up question or having to “memorize” an entire dataset at once. The first option is slow, and because data updates constantly, the numbers may update between pulling information and creating inconsistencies. The second option could overwhelm the LLM because of the amount of information required to keep in its active focus. Neither approach delivered the seamless, conversational experience we wanted. We needed something smarter.
The Core Insight: Store Big, Sample Small, Query on Demand
Our solution emerged from a simple principle: separate what the AI needs to understand from what it needs to store.
When a user asks for campaign data, they want to work with that dataset across multiple turns of conversation. But the AI doesn’t need to see every row to understand what the data represents. A small sample of just a few rows tells the LLM everything it needs to know about column names, data types, and the general shape of the information. The full dataset, meanwhile, can live elsewhere, ready to be queried when needed.
This led us to what we call our “artifacts” system – a memory layer that gives our AI assistant persistent access to datasets without bloating the conversation context.
Long-Term Storage Meets High-Speed Calculation
Our artifacts system relies on two complementary technologies working together.
To keep the system running smoothly, we use two different technologies that act like a digital filing cabinet and a high-speed calculator. PostgreSQL serves as our storage layer, where we save the results of every search as a flexible document. We give each set of data its own unique ID so the AI can easily find it later. We chose this specific storage method because it’s incredibly flexible; it doesn’t care if the data is a simple list of names or a complex table of metrics. This allows us to save any type of information without having to constantly rebuild the system’s underlying structure.
When it’s time to actually work with that data – like filtering a list or calculating a total, we use DuckDB. Think of this as a temporary, high-speed workspace. Because this workspace is built for speed and handles complex math with ease, it can combine different sets of data or perform deep analysis in a fraction of a second. Once the task is finished, the workspace clears itself out, keeping the whole process clean and efficient.
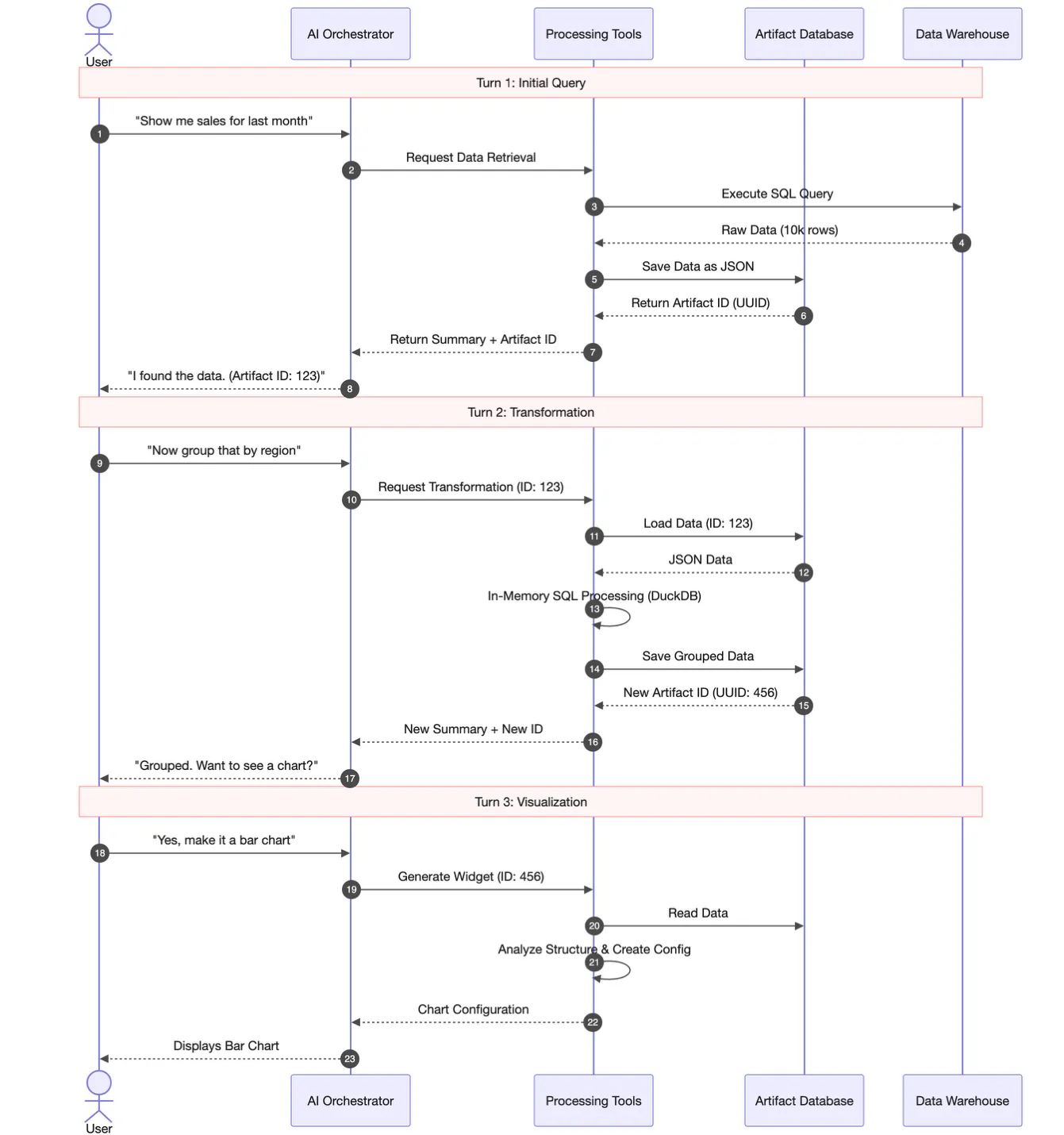
How It Works in Practice
Let’s look at how this process feels for a user in real-time. Imagine that a user asks the AI a starting question: “Show me the spend for my marketing campaigns last week.”
Behind the scenes, our assistant goes to the main data warehouse and pulls back a large table – let’s say 847 rows of performance data. Instead of trying to memorize all 847 rows, the system tucks the full table away into its “digital filing cabinet” and gives it a unique ID. What the AI actually keeps in its active memory is very minimal: just the ID number, the total row count, and a tiny three-row sample. This sample is just enough for the AI to understand what the data looks like – things like “campaign name,” “cost,” and “date.”
When users follow up with a more specific request, like “Which of those campaigns had a low click rate?”, our assistant doesn’t need to go back to the beginning. It simply points to the ID in its filing cabinet and uses DuckDB to filter that specific list. In just a few milliseconds, the system creates a new, smaller list of just the campaigns the user asked for.
This process can keep going for as long as the user needs it. Users can ask the AI to “sum the total cost” or “compare this to last month,” and it will keep referencing and refining those saved files. Each step is extremely fast and perfectly consistent, because the AI is always working from the same “source of truth” that it stored at the very beginning.
The Benefits We’ve Observed
Token efficiency improved dramatically. Instead of context windows filled with repetitive data rows, our conversations stay lean. The AI sees just enough to understand the data, freeing up context space for the actual conversation and reasoning.
Data consistency became automatic. Users can now perform multi-step analyses confident that “the data they’re looking at” remains stable throughout their session. No more subtle inconsistencies from re-querying changing datasets.
Complex workflows became possible. The ability to join multiple artifacts opened up sophisticated analytical patterns. Users can pull data from different time periods, different entity types, or different query paths, and combine them in ways that would be impractical with single-shot database queries.
The architecture scales naturally. Because each artifact is a JSON document with a unique ID, we’re not constrained by predefined schemas. New types of queries and new data shapes work without system changes.
Looking Forward
Our artifacts system has become a foundational component of our AI data assistant, enabling the kind of fluid, multi-turn analytical conversations that feel natural to users accustomed to working with data in spreadsheets or BI tools. The gap between “AI chatbot” and “AI analyst” narrows significantly when the assistant can maintain persistent, queryable context.
As we continue developing our AI capabilities at Nexxen, this memory architecture provides a template for building assistants that not only respond to individual prompts, but truly collaborate with users across extended workflows. The principle remains simple: give AI systems the references they need to stay informed, while keeping the heavy lifting in purpose-built infrastructure.
Read Next




Connect With Us
Learn how you can effectively and meaningfully leverage today’s video and CTV opportunities with our end-to-end platform, data and insights.